
7B的DeepSeek蒸馏Qwen数学超o1!在测试时间强化学习,MIT积分题大赛考93分
7B的DeepSeek蒸馏Qwen数学超o1!在测试时间强化学习,MIT积分题大赛考93分见识过32B的QwQ追平671的DeepSeek R1后——刚刚,7B的DeepSeek蒸馏Qwen模型超越o1又是怎么一回事?新方法LADDER,通过递归问题分解实现AI模型的自我改进,同时不需要人工标注数据。
来自主题: AI技术研报
6708 点击 2025-03-08 10:38
 搜索
搜索
见识过32B的QwQ追平671的DeepSeek R1后——刚刚,7B的DeepSeek蒸馏Qwen模型超越o1又是怎么一回事?新方法LADDER,通过递归问题分解实现AI模型的自我改进,同时不需要人工标注数据。

编辑注:今天上线的Manus引发了全网的 Agent 热潮,Manus 背后的产品团队——Monica.im 的产品团队也引起了大家的关注。Manus产品负责人张涛在 2 月份曾经有过一次公开分享,解读 DeepSeek R1 成功背后的技术进步和产品思路,从中可以一窥 Manus 的部分解题思路。
在 R1 推理模型大火之后,全民接力集成 DeepSeek,有硅基流动这样的大模型云服务平台、有腾讯元宝这样的 Chatbot,甚至微信这样的顶流。但是,AI 图片类产品却鲜少有接入 DeepSeek R1 的新闻,而从 DeepSeek-R1 发布到 Krea 宣布上线新功能仅仅 10 天,这个反应应该是图像产品中最快的。

DeepSeek R1 催化了 reasoning model 的竞争:在过去的一个月里,头部 AI labs 已经发布了三个 SOTA reasoning models:OpenAI 的 o3-mini 和deep research, xAI 的 Grok 3 和 Anthropic 的 Claude 3.7 Sonnet。
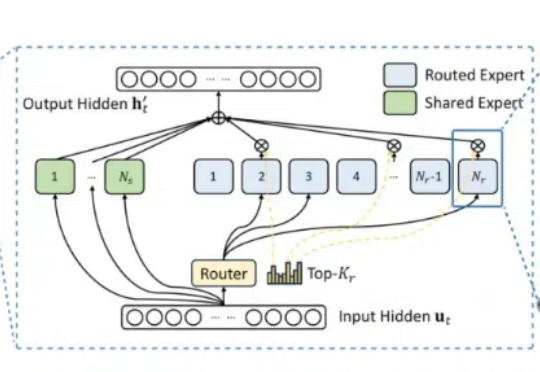
满血版DeepSeek R1部署A100,基于INT8量化,相比BF16实现50%吞吐提升! 美团搜推机器学习团队最新开源,实现对DeepSeek R1模型基本无损的INT8精度量化。
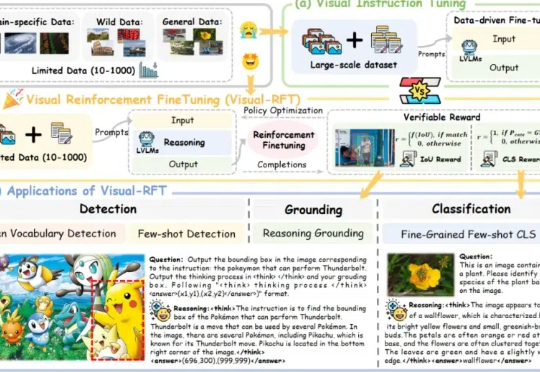
通过针对视觉的细分类、目标检测等任务设计对应的规则奖励,Visual-RFT 打破了 DeepSeek-R1 方法局限于文本、数学推理、代码等少数领域的认知,为视觉语言模型的训练开辟了全新路径!

在 DeepSeek 生成的文本中,有 74.2% 的文本在风格上与 OpenAI 模型具有惊人的相似性?这是一项新研究得出的结论。这项研究来自 Copyleaks—— 一个专注于检测文本中的抄袭和 AI 生成内容的平台。
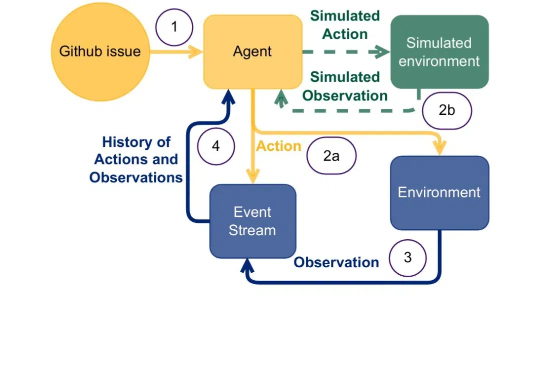
原来,大型推理模型(Large Reasoning Model,LRM)像人一样,在「用脑过度」也会崩溃,进而行动能力下降。

DeepSeek开源AI引爆全民应用潮!飞书多维表格成为最佳入门级方案,如今亚朵星球、茶百道等纷纷接入,让团队如虎添翼显著提升效率。
字节跳动旗下悟空浏览器已正式接入DeepSeek R1模型。